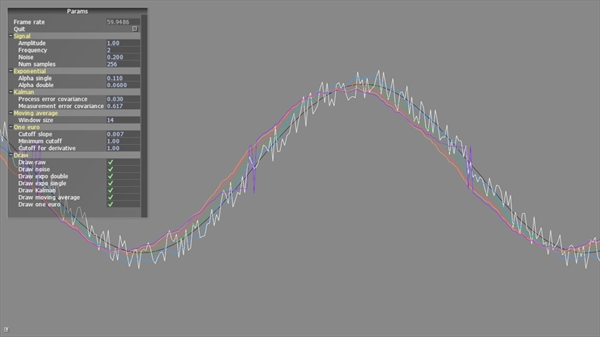
Pictured: Sampling allows implementation of multiple smoothing filters with minimal code I've finally gotten around to publishing what is probably my most useful tool to date. It's called "Sampling". It's nothing groundbreaking. It's basically just a vector which stores data and a map which stores functions. You've probably had to do what Sampling does a million times. What Sampling is more of than a library is a philosophy on how to manage a buffer and leverage C++11's syntax to make processing or analyzing it extremely easy. It's also a nice way to take the legwork out of circular buffering. Sampling is just one header file, compatible with any C++11 or greater environment. Get it here: https://github.com/bantherewind/Sampling There's no need to wrap it, but I have a "block" which demonstrates how to use it in Cinder . Sampling is submoduled in the block's repo. Clone it from here: https://github.com/wieden-kennedy/Cinder-Sampling So far I just have one sample, which emulates the bottom part of this web page: http://www.lifl.fr/~casiez/1euro/InteractiveDemo/ In this sample, a noisy signal is generated to be filtered using five different smoothing algorithms. To run this, I need to declare a SamplerT. sampling::SamplerT<float, float> The first template argument is the stored data type. The second argument is the return type of functions which the Sampler will track. A better way to think of these arguments are as input and output, respectively. That's basically what this is. A sampler stores input values, but only emits outputs. So I've declared a map for those. sampling::SamplerT<float, float> mInput; std::map<size_t, std::vector<float> > mOutput; Samplers only store two samples by default, but that's easy to change: mInput.setNumSamples( 256 ); My input buffer is 256 floats wide. This is managed internally now. But if I want to do some manual management, like insert a float at an arbitrary point or remove data, I have functions for that. If the capacity and actual number of stored items doesn't line up; no biggie. The most common task is simply adding data to the Sampler with pushBack. On every frame, I do some basic math to get the next value in a noisy sine wave. Then I add it to my Sampler. float v = sinf( (float)getElapsedSeconds() ) + randFloat( -0.2f, 0.2f ); mInput.pushBack( v ); Now I update my outputs by running the filters. I have an enumerator called FilterType which helps me organize my algorithms. for ( size_t i = 0; i < (size_t)FilterType_Count; ++i ) { float f = mInput.runProcess( i ); mOutput[ i ].push_back( f ); } //Now I can draw all the signals: for ( const auto& iter : mOutput ) { gl::begin( GL_LINE_STRIP ); float h = (float)getWindowHeight() * 0.5f; float x = (float)getWindowWidth(); const vector<float>& signal = mOutput.at( iter.first ); size_t numSamples = signal.size(); if ( numSamples > 0 ) { float d = x / (float)( mNumSamples - 1 ); for ( size_t i = 0; i < numSamples; ++i, x -= d ) { float y = signal.at( i ) * h * 0.5f + h; gl::vertex( x, y ); } } gl::end(); } The set up is where the magic happens. If you've looked at Kalman or One Euro filters, you probably know they tend to be quite cumbersome. Kalman has a lot to track. One Euro usually has a low pass filter class it implements. For any filter, you're probably used to putting it in its own class, which makes referencing its data a bit verbose. Any parameters controlled by the UI need to be passed into the class instance. It can be a lot of work. Here's a snippet of this app setting up the moving average algorithm. for ( size_t i = 0; i < (size_t)FilterType_Count; ++i ) { mOutput[ i ] = {}; switch ( (FilterType)i ) { ... case FilterType_MovingAverage: mInput.setProcess( i, [ & ]() -> float { float f = 0.0f; if ( !mInput.getSamples().empty() ) { int32_t count = (int32_t)mInput.getNumSamples(); int32_t start = max( count - mMovingAverageWindowSize, 0 ); for ( int32_t i = start; i < count; ++i ) { f += (float)mInput.getSamples().at( i ); } f /= (float)mMovingAverageWindowSize; } return f; } ); break; ... } } Note that I don't have to worry about scope or setting up a class to interface between my main application and the algorithm. This is less critical in this example, but can be a challenge with One Euro. With Sampling, I can just slam in logic in tiny algorithms and the rest of the code above just works. If I want to call a process a la carte... float avg = mInput.runProcess( (size_t)FilterType_MovingAverage ); Filtering is just one thing you can do with this. I've found this to be an easy way to build and manage technologies like gesture and pose recognition ( Kinect , Leap , etc), CV -based motion tracking and smoothing, audio and video effects and processing, tempo detection and other audio analysis, social media feed processing, handwriting recognition, etc. Basically anything where you need to test or process a data set. The Sampling.h file is maybe less something you really even need to download, and more just something to review. Templatizing a wrapper around data and its processors has made this fundamental part of coding dead simple. It's saved me a ton of time. Maybe it will help you, too.
